Test-Time Training Layers: The Next Evolution in Transformer Architecture

In the fast-changing world of AI, a breakthrough innovation has emerged that could change how AI systems process information. Test-Time Training (TTT) layers represent a new approach to how AI models learn and adapt, combining the speed of simpler systems with the power of more complex ones.
The Problem: Speed vs. Power
AI researchers have long faced a tough choice when building systems that process sequences of information (like text or video).
The Transformer Challenge
Current state-of-the-art AI systems (called Transformers) are powerful because they can look at relationships between all parts of a sequence. But this is like trying to keep track of connections between every word in a book at once, the mental effort grows enormously as the book gets longer [1].
The Simpler System Limitation
Older systems (called RNNs) work more like how humans read, processing one word at a time and updating their understanding. This is more efficient, but it's like trying to remember an entire book by keeping just one summary in your head, you inevitably lose important details [2].
The Breakthrough: Test-Time Training Layers
Researchers from several top universities have created a new approach that reimagines how AI systems process information [2]. The key innovation is in how these new layers store information:
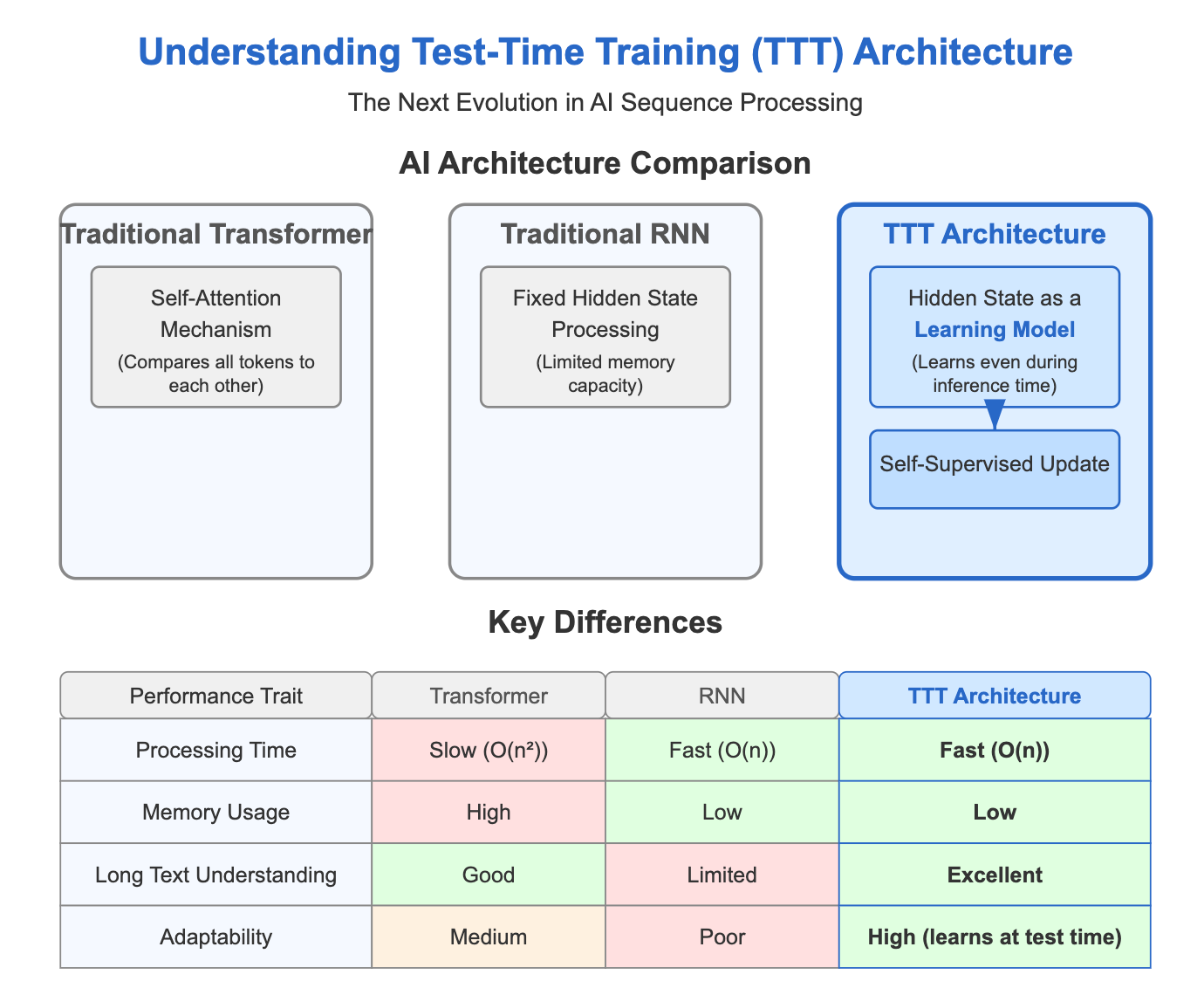
The revolutionary idea behind TTT layers is this: the system's memory itself becomes a mini AI model, and the way it updates this memory is by learning on the fly [2]. Since this learning happens even when processing new information, these layers are called "Test-Time Training" layers.
Think of it like this: instead of just taking notes as you read (traditional AI), TTT is like having a study group in your head that actively discusses and connects new information with what you already know.
"We propose TTT layers, a new class of sequence modeling layers where the hidden state is a model, and the update rule is self-supervised learning. Our perspective that the forward pass of a layer contains a training loop itself opens up a new direction for future research."
Two Key Versions
The researchers created two main versions of TTT layers [2]:
- TTT-Linear: Uses a simple mathematical model as memory (like keeping basic notes)
- TTT-MLP: Uses a more complex model as memory (like having more detailed and interconnected notes)
Both versions maintain the speed advantage of simpler systems while dramatically improving their ability to understand complex information.
Performance Breakthroughs

Impressive Results
TTT layers have shown remarkable performance across various tests. When tested with different sizes (from smaller to larger models), both TTT versions matched or beat traditional AI systems [2].
The results are especially impressive when processing long texts. TTT layers continue to improve their understanding when given more context, while other approaches plateau after about 16,000 tokens (roughly the length of a short story) [2].
This is like the difference between a student who gets confused after reading too much information versus one who gets better at connecting ideas the more they read.
Speed Benefits
One of the biggest practical advantages of TTT layers is speed. With initial optimizations, TTT-Linear is already faster than traditional Transformer systems when handling sequences of 8,000 tokens (about the length of a long article) [2].
This speed improvement comes from two clever techniques 2:
- Mini-batch TTT: Processing multiple pieces of information at once, like reading several sentences together rather than word by word
- Dual form implementation: A mathematically equivalent but faster approach that better uses modern computer hardware
Beyond Text: Video Applications
TTT layers work for more than just text. Researchers have successfully used them to generate one-minute videos from text descriptions, creating videos with consistent characters and smooth motion [3].
When compared to other approaches, TTT layers generated more coherent videos where characters remained consistent throughout the entire video [3].
The Science Behind It
The success of TTT layers isn't just based on experiments,it's supported by mathematical proof. Research has shown that test-time training methods can demonstrably improve how AI systems learn from context [4].
A comprehensive analysis has shown that TTT can:
- Clarify how the initial training affects performance on new tasks
- Explain how TTT helps AI systems adapt to new situations
- Show that TTT significantly reduces the amount of examples needed for an AI to learn effectively [4]
The Future of AI: A New Chapter with TTT Layers
While TTT-Linear is already showing impressive results, TTT-MLP shows even greater potential for handling long texts, though it still faces some technical challenges [2]. This breakthrough opens an exciting path forward for AI design, representing more than just an improvement, it's a fundamental shift in how we think about these systems.
Think of traditional AI like a student who can only recall what they've memorized. In contrast, TTT creates AI systems more like students who can actively think through new problems using principles they've learned. By embedding learning within every step of information processing, TTT layers blur the line between training and using an AI.
This means future AI could adapt more effectively to new information, similar to how a person quickly understands a new situation. It could rapidly process vast amounts of data without becoming overwhelmed. Additionally, it could sustain consistent performance over time, much like how the human brain remains engaged when reading a lengthy story.
This breakthrough could revolutionize AI across multiple disciplines by seamlessly integrating diverse architectural strengths. It has the potential to transform computing from rigid calculators into intuitive assistants capable of continuous learning and collaboration, fundamentally reshaping our interaction with technology.
References
- "Transformer (deep learning architecture)," Wikipedia, 2025, [Online]
- Various Authors, "Learning to (Learn at Test Time): RNNs with Expressive Hidden States," ArXiv, 2024, [Online]
- Test-Time Training Project, "One-Minute Video Generation with Test-Time Training," 2024, [Online]
- Various Authors, "Test-Time Training Provably Improves Transformers as In-context Learners," ArXiv, 2025, [Online]
Synergizing Specialized Reasoning and General Capabilities in AI
A comprehensive exploration of methods for integrating specialized reasoning models with general-purpose language models to enhance AI capabilities.
The Rise of AI Agents in Cyberattacks: Latest Research and Threats
An analysis of the emerging threat landscape as AI agents become tools for cyber criminals
Discuss This with Our AI Experts
Have questions about implementing these insights? Schedule a consultation to explore how this applies to your business.