Metacognitive Reinforcement Learning for Self-Improving AI Systems
Unlocking Autonomous Self-Improvement Through Meta-Level Learning
The quest to create truly autonomous, self-improving artificial intelligence has led researchers to explore how machines might monitor and enhance their own cognitive processes. At the intersection of metacognition and reinforcement learning lies a promising framework for AI systems that can evaluate their own performance, identify limitations, and adapt accordingly, without human intervention.

The Foundations of Metacognitive AI
Metacognition, the ability to monitor and control one's own cognitive processes, has long been considered a uniquely human capability. However, researchers are now implementing these capabilities in AI systems through what's known as metacognitive reinforcement learning where systems can "self-monitor their own decision-making processes and ongoing performance, and make targeted changes to their beliefs and action-determining components" [4].
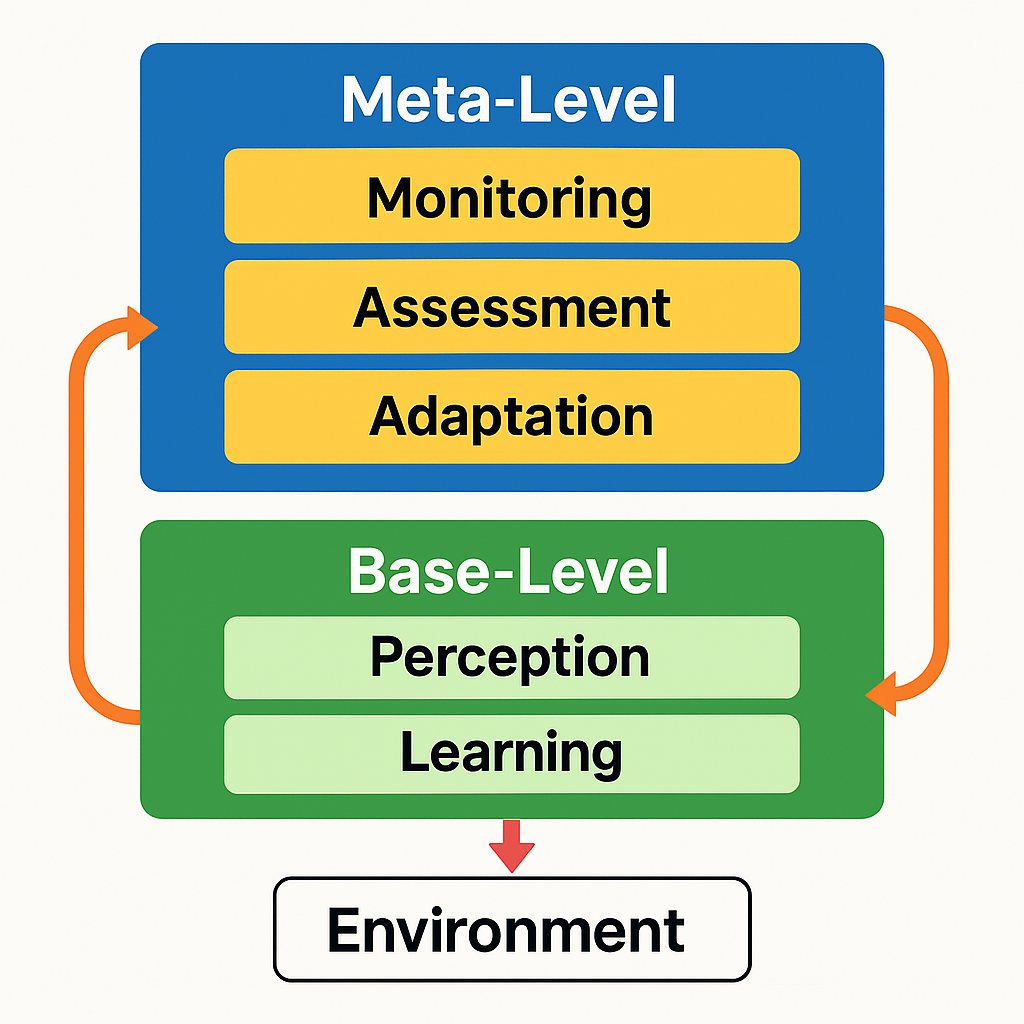
The core concept revolves around creating AI architectures that operate on two distinct yet interconnected levels. At the base level, cognition involves the primary task-solving processes that interact directly with the environment. Above this, meta-level cognition encompasses the processes that monitor, evaluate, and modify these base-level functions, creating a form of computational self-awareness.
This approach is gaining traction because it addresses one of the most significant challenges in AI development; brittleness. Implementing a metacognitive loop (MCL) enables intelligent systems to "cope with the unexpected problems and events that are the inevitable result of real-world deployment" [4]. Rather than requiring human intervention when encountering novel situations, these systems can autonomously adapt, learning not just from the environment but from their own cognitive processes and limitations.
The Metacognitive Loop: A Framework for Self-Improvement
The Metacognitive Loop (MCL) provides a structured approach to self-improvement in AI systems through a continuous cycle of self-observation and adjustment. This process helps "intelligent systems cope with the perturbations that are the inevitable result of real-world deployment" [4] through three interconnected phases of metacognitive processing.
The monitoring phase forms the foundation of metacognitive awareness, as the AI system continuously observes its own decision-making processes and outcomes. Here, the system tracks performance metrics, compares actual outcomes against expected results, and flags unexpected behaviors or suboptimal performance [4]. This self-monitoring creates the necessary data stream for metacognitive reasoning.
When monitoring detects an anomaly, the assessment phase begins. The metacognitive layer analyzes the situation to determine the cause, diagnosing errors in the system's knowledge, reasoning processes, or learning mechanisms using domain-general reasoning about failures [4]. This diagnostic capability represents a sophisticated form of computational introspection that traditional AI frameworks lack.
Based on this assessment, the adaptation phase implements appropriate adjustments to the system's cognitive processes. These modifications might include updating the knowledge base, adjusting learning rates or confidence thresholds, or fundamentally restructuring approaches to problem-solving [4]. The cycle then continues, with the monitoring phase observing the effects of these adaptations, creating a continuous loop of metacognitive improvement.
Reinforcement Learning as a Mechanism for Metacognition
Reinforcement learning (RL) provides a natural framework for implementing metacognitive processes in AI systems. Recent research has demonstrated that "reinforcement learning of motor learning properties" can create "a minimal mechanism" that "regulates a policy for memory update... while monitoring its performance" [1].
"The model comprises a modular hierarchical reinforcement-learning architecture of parallel and layered, generative-inverse model pairs."
— Kawato & Cortese, Biological Cybernetics
In this framework, a higher-level RL system learns to optimize the parameters and behaviors of a lower-level RL system. This "modular hierarchical reinforcement-learning architecture" [2] creates a powerful paradigm for self-improvement. The meta-level system receives rewards based on the base system's performance, explores different configurations of the base system, learns which modifications lead to optimal outcomes in different contexts, and adjusts the base system accordingly.
This approach moves beyond traditional RL by incorporating self-reflection mechanisms that evaluate not just what actions to take, but how to learn better. By turning the reinforcement learning paradigm inward, these systems can optimize their own learning processes, achieving a form of self-directed cognitive evolution that mimics aspects of human metacognition.
Practical Architectures for Self-Improving AI Systems
Several promising architectural approaches have emerged in recent research, each addressing different aspects of metacognitive reinforcement learning. These frameworks provide practical implementations that move beyond theoretical constructs to create systems capable of genuine self-improvement.
The TRAP framework represents one comprehensive approach, identifying four essential aspects of metacognitive AI: "transparency, reasoning, adaptation, and perception" [9]. Transparency ensures that the system can represent its internal states and processes in a way that facilitates self-monitoring. Reasoning capabilities enable higher-order thinking about the system's own cognition. Adaptation mechanisms allow the system to modify its learning and decision-making strategies based on this reasoning. Perception capabilities encompass both external environmental awareness and internal performance assessment.
Safety remains a critical concern for autonomous AI systems, particularly those capable of self-modification. Recent work on "assured learning-enabled autonomy" has shown how "adapting the reward function parameters of the RL agent" through "a metacognitive decision-making layer" can "assure that the learned policy by the RL agent satisfies safety constraints" [11]. This approach ensures that self-improving systems remain within safe operational parameters even as they adapt and evolve their capabilities.
Feedback Loops for Self-Improvement
Effective self-improvement relies on well-designed feedback mechanisms that flow between metacognitive layers. These feedback loops "provide the necessary mechanism for the system to evaluate its performance and make adjustments to its learning strategy" [8], creating a continuous cycle of assessment and refinement. Through these cycles, metacognitive systems engage in a form of computational introspection, analyzing not just the outcomes of their actions but the effectiveness of their learning processes, driving increasingly sophisticated behavior that can adapt to novel situations without external guidance.
Applications and Future Directions
The integration of metacognition into reinforcement learning systems opens exciting possibilities across multiple domains, with applications already emerging in several fields.
In robotics and motor learning, research has demonstrated how "autonomous self-improving robots that interact and improve with experience" can leverage "online model-free reinforcement learning on top of offline model-based learning" [7]. This enables robots to rapidly adapt to new environments and tasks while continuously refining their capabilities. The metacognitive layer allows these systems to transfer learning across different contexts, generalizing from past experiences to novel situations in ways that traditional reinforcement learning struggles to achieve.
Academic and educational applications present both opportunities and challenges. Research has shown that AI technologies may sometimes lead to "metacognitive 'laziness'" that can "hinder users' ability to self-regulate and engage deeply in learning" [3]. However, properly designed metacognitive systems could enhance learning by modeling and supporting effective cognitive strategies. By understanding and adapting to individual learning patterns, these systems could provide personalized educational support that evolves alongside the learner.
One particularly fascinating application involves AI systems functioning as "co-scientists" that leverage "test-time compute scaling to iteratively reason, evolve, and improve outputs" through "recursive self-critique" [10]. Such systems could accelerate scientific discovery by generating and refining hypotheses through metacognitive processes. By applying metacognitive evaluation to their own scientific reasoning, these AI co-scientists can potentially identify novel connections and research directions that human scientists might overlook.
Current Challenges and Limitations
Despite promising advances, several challenges remain in developing truly self-improving AI systems. These limitations represent important areas for future research and development.
Complexity trade-offs present a significant challenge, as more sophisticated metacognitive mechanisms require additional computational resources, potentially slowing down the base-level processing. Finding the right balance between metacognitive depth and computational efficiency remains an open question, particularly for systems intended to operate in real-time environments.
Meta-level optimization poses another difficult problem, as determining how to reward the meta-level system remains challenging, particularly when the ultimate goals involve long-term improvement rather than immediate performance. Developing appropriate reward functions for metacognitive processes requires sophisticated approaches that can evaluate not just task performance but learning efficiency and adaptability.
Transfer learning represents both an opportunity and a challenge. While some research has shown that "metacognitive reinforcement learning" can lead to "transfer effects" that are "retained for at least 24 hours after the training" [12], creating systems that can transfer learning across significantly different domains remains challenging. The ultimate goal of metacognitive systems is to develop general learning capabilities that can apply across diverse tasks and environments.
Safety assurance becomes increasingly critical as AI systems gain the ability to modify themselves. Ensuring these systems remain aligned with human values and operate within safe parameters requires "self-awareness, self-healing, and self-management" mechanisms that "avoid failure modes and ensure that only desired behavior is permitted" [5]. This represents perhaps the most important challenge in metacognitive AI development, as self-modifying systems inherently introduce risks of unpredictable behavior.
Toward Truly Autonomous Self-Improvement
The path to genuinely autonomous, self-improving AI systems will likely require integrating multiple approaches to metacognition and reinforcement learning.
Recursive self-improvement represents one promising direction, where an AI can "recursively self-prompt itself to achieve a given task or goal, creating an execution loop which forms the basis of an agent that can complete a long-term goal or task through iteration" [6]. This approach creates a form of meta-learning where the system continuously refines not just its performance but its learning processes, potentially leading to accelerating improvements over time.
Neurosymbolic approaches offer another valuable perspective, combining neural networks with symbolic reasoning to create systems that can better "reason about, appropriately classify and respond to the performance anomalies it detects" [4]. This hybrid approach leverages the pattern recognition strengths of neural networks while incorporating the interpretability and reasoning capabilities of symbolic systems, creating more robust metacognitive architectures.
Human-inspired metacognition provides a rich source of inspiration, drawing from cognitive psychology to implement metacognitive strategies that have evolved to be effective in complex, uncertain environments [12]. By understanding how humans monitor and regulate their own learning processes, researchers can design AI systems that implement similar strategies, potentially achieving more human-like adaptability and learning efficiency.
The Future
Metacognitive reinforcement learning represents a significant step toward creating truly autonomous, self-improving AI systems. By enabling machines to monitor and modify their own cognitive processes, we open possibilities for systems that can adapt to novel situations, recover from failures, and continuously enhance their capabilities without human intervention.
As this field continues to evolve, we can expect to see increasingly sophisticated implementations of metacognitive mechanisms in AI systems across diverse domains—from robotics and autonomous vehicles to scientific research assistants and educational tools. The challenge will be balancing the power of self-improvement with appropriate safety guarantees and alignment with human values [5].
The ultimate goal remains clear: AI systems that can not only learn from experience but can learn how to learn better—a capacity that may one day approach the remarkable adaptability and creativity of human cognition. By continuing to explore and refine metacognitive reinforcement learning approaches, we move closer to AI systems that truly understand and improve themselves, opening new frontiers in artificial intelligence research and application.
References
- Sugiyama, T. et al., "Reinforcement learning establishes a minimal metacognitive process to monitor and control motor learning performance," Nature Communications, vol. 14, no. 1, pp. 3824, 2023, [Online]
- Kawato, M. & Cortese, A., "From internal models toward metacognitive AI," Biological Cybernetics, vol. 115, no. 5, pp. 415-430, 2021, [Online]
- Fan, Y. et al., "Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance," British Journal of Educational Technology, 2025, [Online]
- Anderson, M.L., Oates, T., Chong, W., & Perlis, D., "The metacognitive loop I: Enhancing reinforcement learning with metacognitive monitoring and control for improved perturbation tolerance," Journal of Experimental & Theoretical Artificial Intelligence, vol. 18, no. 3, pp. 387-411, 2006, [Online]
- Johnson, J., "Metacognition for artificial intelligence system safety – An approach to safe and desired behavior," Safety Science, vol. 154, 2022, [Online]
- "Recursive self-improvement," Wikipedia, 2025, [Online]
- Hirose, N. et al., "SELFI: Autonomous Self-Improvement with Reinforcement Learning for Social Navigation," ArXiv, 2024, [Online]
- "Recursive Self-Improvement in AI: The Technology Driving Allora's Continuous Learning," Nodes.Guru, 2024, [Online]
- Various authors, "Metacognitive AI: Framework and the Case for a Neurosymbolic Approach," ArXiv, 2024, [Online]
- "Accelerating scientific breakthroughs with an AI co-scientist," Google Research Blog, 2024, [Online]
- Mustafa, A. et al., "Assured Learning-enabled Autonomy: A Metacognitive Reinforcement Learning Framework," ArXiv, 2021, [Online]
- Lieder, F., "METACOGNITIVE REINFORCEMENT LEARNING," ResearchGate, 2023, [Online]
Discuss This with Our AI Experts
Have questions about implementing these insights? Schedule a consultation to explore how this applies to your business.