The Data Infrastructure AI-Native Systems Can't Ignore
Embedding Pipelines, Vector Databases, and Why the Data Layer Matters

When a production AI system returns an outdated answer, retrieves the wrong document, or confidently describes a policy that changed three months ago, the temptation is to blame the model. In most cases, the model is not the problem. The failure lives further back in the pipeline, in the data infrastructure that transforms raw information into the context the model consumes. Architectural conversations about AI-Native systems spend considerable energy on model routing, agent orchestration, and governance layers. The data layer receives far less attention, yet it is the foundation everything else depends on. Embedding pipelines, vector databases, versioning strategies, and the tension between real-time and batch processing are not implementation details to be resolved after the architecture is defined. They are architectural decisions with consequences that compound over time.
The Embedding Pipeline and Its Hidden Decisions
Retrieval-Augmented Generation, or RAG, is the practice of supplying a language model with relevant documents retrieved at query time rather than relying solely on knowledge baked into the model's parameters. The retrieval mechanism depends on embeddings, numerical vector representations that capture the semantic meaning of text. Building those representations requires a pipeline, a series of choices that teams may treat as setup steps rather than ongoing engineering responsibilities.
The first choice is chunking, deciding how to divide source documents into pieces small enough to retrieve meaningfully. Chunks that are too small lose context needed to answer questions. Chunks that are too large inject noise and reduce precision [1]. The right strategy varies by document type, video transcripts require different handling than legal contracts, and there is no universal answer. The second choice is the embedding model, which determines how semantic meaning is encoded. Changing the embedding model after deployment requires re-indexing every document in the store, a cost that scales with corpus size and is often underestimated at design time [1].
These decisions are not one-time. As source documents evolve, the pipeline must run again. When the corpus grows, indexing time grows with it. When an embedding model is updated by its provider, the entire store may become semantically inconsistent, some documents encoded with one model, others with another. The embedding pipeline is a living system, not a deployment artifact.
Vector Databases
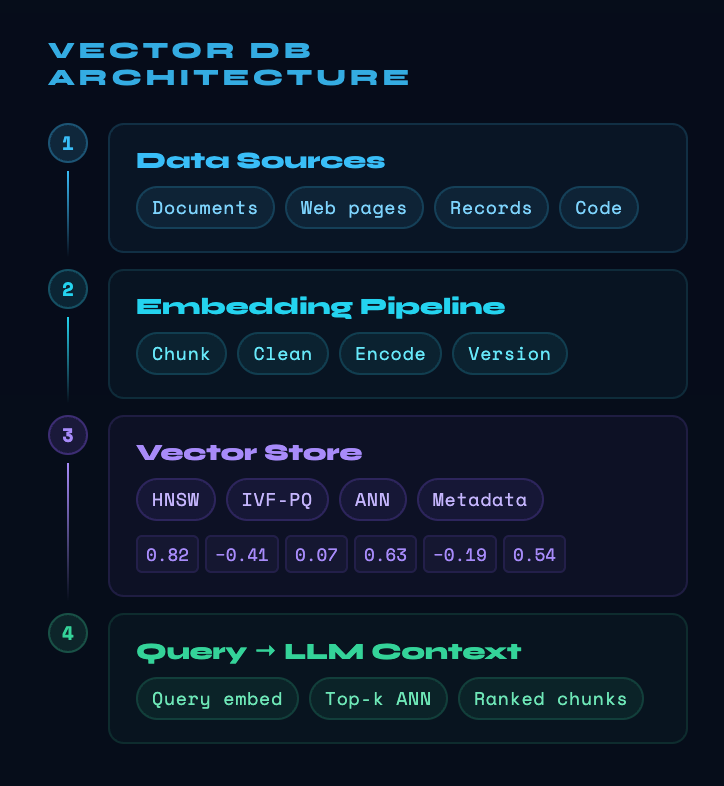
More Than a Storage Layer
A vector database stores embeddings and answers queries by finding the stored vectors most similar to a query vector. The challenge is that exact similarity search across millions of high-dimensional vectors is computationally expensive, so production systems use approximate nearest neighbor algorithms that trade a small amount of recall accuracy for a large reduction in latency [2]. The acceptable point on that trade-off depends on the application. A legal research assistant may require higher recall than a product recommendation engine, and the indexing strategy must reflect that. Testing and validation of vector search systems remains an immature discipline, with most current methodologies focused on isolated benchmarks rather than behavior under the dynamic scaling and hybrid query conditions that real-world deployments demand [2].
Multi-stage inference pipelines reveal the operational consequences of vector database design decisions. When retrieval, reasoning, and generation happen in sequence, the memory bandwidth demands of the retrieval stage can create bottlenecks that affect the latency of every subsequent step. The architectural implications of remote vector retrieval compound when retrieval is itself distributed, requiring orchestration across memory hierarchies that interact in ways a simple benchmark cannot reveal [3]. Vector database selection is therefore not a preference but an architectural commitment with downstream effects that surface only at production scale.
The Freshness Problem
Static knowledge is a silent hazard in AI-Native systems. A vector store built in one month may contain policies, prices, or procedures that change the next. When a user asks a question whose correct answer depends on which version of a document was in effect, a retrieval system without temporal awareness will retrieve the semantically closest result regardless of whether it is still valid.
Research on version-aware retrieval makes the scale of this problem concrete. Standard RAG approaches achieve only around 58 to 64 percent accuracy on questions where the answer depends on knowing which version of a document applies, because those systems retrieve semantically similar content without checking whether that content remains current [4]. Versioned document structures that track content boundaries and changes between document states can raise accuracy dramatically, but they require the data pipeline to carry version metadata from ingestion through indexing and into retrieval [4].
This is where RAGOps, the operational discipline governing retrieval-augmented generation systems in production, becomes relevant. RAGOps treats data management as a lifecycle equal in importance to the query processing lifecycle. Data updates are not background maintenance tasks but a continuous engineering responsibility requiring automated validation, re-indexing triggers, and quality checks to ensure that what the retriever returns is both semantically relevant and temporally valid [5].
Real-Time Versus Batch
Batch Pipelines
Scheduled jobs process documents in bulk, rebuild indexes periodically, and favor throughput over freshness. Suitable for knowledge bases where sources change infrequently and where the cost of continuous re-indexing would exceed the value of near-real-time accuracy.
Streaming Pipelines
Events trigger incremental updates as source documents change, keeping the knowledge store synchronized with its sources. Required for systems where decisions depend on current information, but demanding in terms of operational complexity and infrastructure cost.
Content-Aware Streaming
An emerging direction suggests aligning processing boundaries with shifts in content meaning rather than fixed time or count intervals [6].
Neither batch nor streaming is universally superior. The choice depends on how quickly source data changes, how much latency is acceptable between a document update and that update becoming retrievable, and what the system can afford to compute continuously. Agentic retrieval systems that execute multi-step queries across heterogeneous data sources add further pressure, because each retrieval hop may touch data at different freshness levels, creating consistency challenges that batch pipelines cannot address and that streaming pipelines solve only at significant cost [7].
MLOps research confirms that data versioning, lineage tracking, and governance are central responsibilities in the machine learning lifecycle, not optional additions. Managing dependencies between model versions and the dataset versions on which they were evaluated is the prerequisite for reproducibility in any system where both data and models evolve over time [8]. AI-Native systems inherit this requirement and intensify it, because the knowledge a retrieval system provides at inference time is functionally equivalent to the training data a model was built on, shaping every answer the system produces.
What This Means
The data layer is not downstream of architecture. It is part of architecture. Decisions about chunking, embedding model selection, vector store design, freshness strategies, and streaming versus batch processing are made at design time, but their consequences persist through every deployment, every model update, and every expansion of the knowledge corpus. Teams that treat these decisions as infrastructure setup rather than ongoing engineering discipline will find them surfacing later as unexplained quality degradation, retrieval failures under load, or answers that were correct when the system launched and wrong three months later. The comprehensive observability that AI-Native architectures require applies to the data layer as much as to the models that consume it. Tracing a retrieval failure back to a stale document or a mis-sized chunk requires instrumentation that begins at ingestion, not at inference.
References
- S. Barnett et al., "Seven Failure Points When Engineering a Retrieval Augmented Generation System," arXiv, 2024, [Online]
- S. Wang et al., "Towards Reliable Vector Database Management Systems: A Software Testing Roadmap for 2030," arXiv, 2025, [Online]
- A. Bambhaniya et al., "Understanding and Optimizing Multi-Stage AI Inference Pipelines," arXiv, 2025, [Online]
- D. Huwiler et al., "VersionRAG: Version-Aware Retrieval-Augmented Generation for Evolving Documents," arXiv, 2025, [Online]
- X. Xu et al., "RAGOps: Operating and Managing Retrieval-Augmented Generation Pipelines," arXiv, 2025, [Online]
- S. Chen et al., "Continuous Prompts: LLM-Augmented Pipeline Processing over Unstructured Streams," arXiv, 2025, [Online]
- A. Singh et al., "Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG," arXiv, 2025, [Online]
- B. Eken et al., "A Multivocal Review of MLOps Practices, Challenges and Open Issues," arXiv, 2024, [Online]
Designing for Graceful Failure in Compound AI Systems
When one agent hallucinates, times out, or returns nonsense, the system must still stand. Practical patterns for resilience in multi-agent AI architectures.
Testing What Can't Be Predicted
How do you test a system where outputs are non-deterministic, components adapt over time, and failure looks like subtle degradation rather than a crash? Evaluation strategies for AI-Native systems demand an entirely new playbook.
Discuss This with Our AI Experts
Have questions about implementing these insights? Schedule a consultation to explore how this applies to your business.